
PHPでスクレイピングにトライしてみたので備忘録も兼ねてメモを残す。
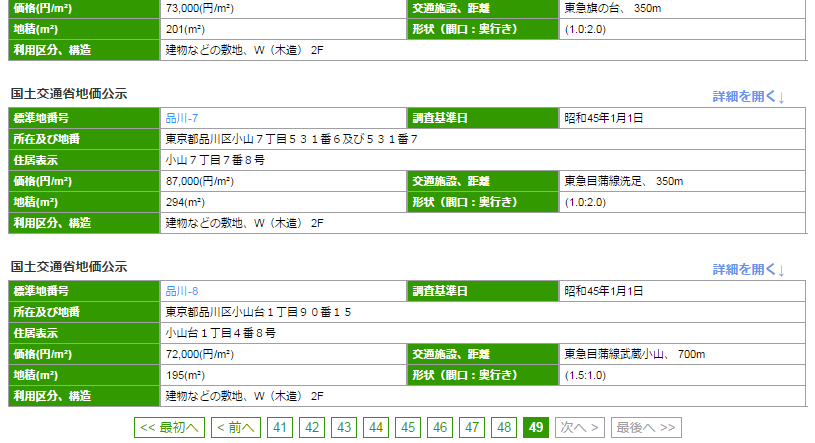
対象とするWebサイトは下記のページ。
エリアや期間、その他絞り込みオプションを指定してから検索をするとそのエリアの地価の詳細情報が画面に表示されるというものである。例えば、品川区の昭和45年から平成27年の住宅地の情報で絞り込むと979件。1ページに20件表示で49ページに分割されて表示される。この情報をスクレイピングしたい。
スクレイピングに関しては以前にも少し試した事があるのだが、Simple HTML DOM Parserというライブラリを利用していきたいと思う。Simple HTML DOM Parserの詳しい使い方については解説をしないので詳細については下記ページからご覧いただきたい。
http://simplehtmldom.sourceforge.net/
まずはこのページからsimplehtmldom_1_5.zipをダウンロードする。
simplehtmldom_1_5.zipを解凍して、simple_html_dom.phpをinclude_onceで読み込んで使う。
<?php
include_once('simplehtmldom_1_5/simple_html_dom.php');
?>
まずは先程のURLを読み込んでみる。とりたい価格などの情報については該当のページのHTMLを見るとdiv classで「datavalue」というのと「datavalue2」というふたつがあてられている事が分かったのでfindの中身をカンマ区切りで複数指定する。
<?php
include_once('simplehtmldom_1_5/simple_html_dom.php');
$url = 'http://www.land.mlit.go.jp/landPrice/SearchServlet?MOD=2&TDK=&SKC=13109&CHI=&YFR=1970&YTO=2015&YOU=0&PFR=&PTO=&PG=1&LATEST_YEAR=';
$contents = file_get_contents($url);
$content = mb_convert_encoding($contents, 'UTF-8', 'auto');
$html = str_get_html($content);
$result = $html->find( 'div[class=datavalue],div[class=datavalue2]' );
foreach($result as $element){
echo $element->plaintext;
}
?>
すると見事に文字化けをした。
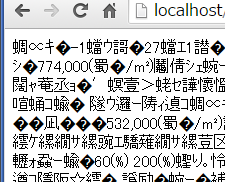
なので頭に下記2行を追加したら文字化けは直って無事に情報は取得できた。
header("Content-Type: text/html; charset=UTF-8");
mb_language("Japanese");
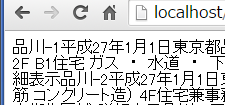
続いて、情報は一旦csvファイルにしたいと思うのでカンマを入れていく。何行目で次の行に折り返すかを確認してみると内容(番号とか価格とか日付とか)が19件で次の情報に行く事が分かった。
配列としては $result[0]->plaintext から順番に吐き出されていくので$result[18]から19ずつで[18]、[37]、[56]と折り返したいところだけはカンマではなく改行を入れたい。
なので下のようなかたちで分岐をさせた。回数をカウントして、回数を19で割った数字の余りが1になるときにだけカンマではなく改行をつける事にした。
<?php
header("Content-Type: text/html; charset=UTF-8");
mb_language("Japanese");
include_once('simplehtmldom_1_5/simple_html_dom.php');
$url = 'http://www.land.mlit.go.jp/landPrice/SearchServlet?MOD=2&TDK=&SKC=13109&CHI=&YFR=1970&YTO=2015&YOU=0&PFR=&PTO=&PG=1&LATEST_YEAR=';
$contents = file_get_contents($url);
$content = mb_convert_encoding($contents, 'UTF-8', 'auto');
$html = str_get_html($content);
$result = $html->find( 'div[class=datavalue],div[class=datavalue2]' );
$i = 0;
foreach($result as $element){
if( ($i % 19) == 18 ){
echo $element->plaintext . PHP_EOL;
}else{
echo $element->plaintext . ',';
}
$i++;
}
?>
問題なさそうなのでcsvに出力するコードを追加する。
test.csvというファイルに上書きをする設定にした。
<?php
header("Content-Type: text/html; charset=UTF-8");
mb_language("Japanese");
include_once('simplehtmldom_1_5/simple_html_dom.php');
$url = 'http://www.land.mlit.go.jp/landPrice/SearchServlet?MOD=2&TDK=&SKC=13109&CHI=&YFR=1970&YTO=2015&YOU=0&PFR=&PTO=&PG=1&LATEST_YEAR=';
$contents = file_get_contents($url);
$content = mb_convert_encoding($contents, 'UTF-8', 'auto');
$html = str_get_html($content);
$result = $html->find( 'div[class=datavalue],div[class=datavalue2]' );
$i = 0;
foreach($result as $element){
if( ($i % 19) == 18 ){
$fp = fopen("test.csv", "a");
fwrite($fp, $element->plaintext . PHP_EOL);
fclose($fp);
echo $element->plaintext . PHP_EOL;
}else{
$fp = fopen("test.csv", "a");
fwrite($fp, $element->plaintext . ',');
fclose($fp);
echo $element->plaintext . ',';
}
$i++;
}
?>
実行後に生成されたcsvファイルを開く。ちなみにエクセルでこのcsvファイルを開く際には文字コードをUTF-8からShift-JISに変換してからでないと文字化けをしてしまう。
文字コードを変換してエクセルで中身を確認するとどうも順番がばらついていておかしい。良く見てみると価格の部分が「1,010,000」とカンマが含まれている事に気が付いた。仕方がないのでそれぞれの前後をダブルクォーテーションで囲むことにした。ついでに画面表示のechoは一旦必要ないので外した。
<?php
header("Content-Type: text/html; charset=UTF-8");
mb_language("Japanese");
include_once('simplehtmldom_1_5/simple_html_dom.php');
$url = 'http://www.land.mlit.go.jp/landPrice/SearchServlet?MOD=2&TDK=&SKC=13109&CHI=&YFR=1970&YTO=2015&YOU=0&PFR=&PTO=&PG=1&LATEST_YEAR=';
$contents = file_get_contents($url);
$content = mb_convert_encoding($contents, 'UTF-8', 'auto');
$html = str_get_html($content);
$result = $html->find( 'div[class=datavalue],div[class=datavalue2]' );
$i = 0;
foreach($result as $element){
if( ($i % 19) == 18 ){
$fp = fopen("test.csv", "a");
fwrite($fp, '"' . $element->plaintext . '"' . PHP_EOL);
fclose($fp);
}else{
$fp = fopen("test.csv", "a");
fwrite($fp, '"' . $element->plaintext . '",');
fclose($fp);
}
$i++;
}
?>
無事に20件分の情報がきれいにとれた。
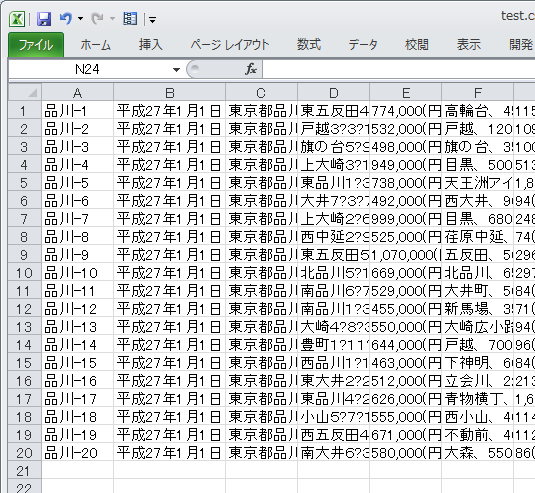
続いて、複数のページをまとめてとってくる処理へ進めていきたい。
対象のページはURLのパラメーター部分のPG=がページ数だという事は確認できた。
まず、いま書いてきたコードは関数にしたいのでfunctionで括る。その上で引数を使ってURLを渡すように変更する。
<?php
function getdata($url){
header("Content-Type: text/html; charset=UTF-8");
mb_language("Japanese");
include_once('simplehtmldom_1_5/simple_html_dom.php');
$contents = file_get_contents($url);
$content = mb_convert_encoding($contents, 'UTF-8', 'auto');
$html = str_get_html($content);
$result = $html->find( 'div[class=datavalue],div[class=datavalue2]' );
$i = 0;
foreach($result as $element){
if( ($i % 19) == 18 ){
$fp = fopen("test.csv", "a");
fwrite($fp, '"' . $element->plaintext . '"' . PHP_EOL);
fclose($fp);
}else{
$fp = fopen("test.csv", "a");
fwrite($fp, '"' . $element->plaintext . '",');
fclose($fp);
}
$i++;
}
}
$url = 'http://www.land.mlit.go.jp/landPrice/SearchServlet?MOD=2&TDK=&SKC=13109&CHI=&YFR=1970&YTO=2015&YOU=0&PFR=&PTO=&PG=1&LATEST_YEAR=';
getdata($url);
?>
これで動作確認がOKだったので、URLのPG=の値をfor文で加算しながら繰り返し実行させる。
とりあえず10ページ分200件をとれるか動かしてみる。
<?php
function getdata($url){
header("Content-Type: text/html; charset=UTF-8");
mb_language("Japanese");
include_once('simplehtmldom_1_5/simple_html_dom.php');
$contents = file_get_contents($url);
$content = mb_convert_encoding($contents, 'UTF-8', 'auto');
$html = str_get_html($content);
$result = $html->find( 'div[class=datavalue],div[class=datavalue2]' );
$i = 0;
foreach($result as $element){
if( ($i % 19) == 18 ){
$fp = fopen("test.csv", "a");
fwrite($fp, '"' . $element->plaintext . '"' . PHP_EOL);
fclose($fp);
}else{
$fp = fopen("test.csv", "a");
fwrite($fp, '"' . $element->plaintext . '",');
fclose($fp);
}
$i++;
}
}
for($i = 1; $i <=10; $i++){
$url = 'http://www.land.mlit.go.jp/landPrice/SearchServlet?MOD=2&TDK=&SKC=13109&CHI=&YFR=1970&YTO=2015&YOU=0&PFR=&PTO=&PG=' . $i . '&LATEST_YEAR=';
getdata($url);
}
?>
無事に動いたのだが、なんと条件によっては19行で折り返しではなく18行で折り返しの事もあり順番が崩れてしまった。内容を見てみると「詳細表示」という項目がない事もあるようで、ない場合は18行で折り返しになってしまう事が分かった。
繰り返し処理の中で詳細表示がなければ18行目折り返しという条件も不可能なように思えたので、いっその事「詳細表示」自体を配列から削除してすべてを18行目折り返しにする事にした。
array_searchで”詳細表示”を探して、もし存在すればunsetで削除、削除した後に配列の番号が歯抜けになってしまうのでarray_valuesで詰めるようにトライした。
しかし試してみると、$element->plaintextに対してarray_searchで”詳細表示”を探してみてもなぜか見つからない。
仕方がないので新しい配列を作成して、その中にarray_pushで$element->plaintextの中身を入れ直して、その後にarray_searchで”詳細表示”を探してみると見つかった。
$newArray = array();
foreach($result as $element){
array_push($newArray,$element->plaintext);
}
if(($key = array_search("詳細表示", $newArray)) !== false){
unset($newArray[$key]);
}
詳細表示を探して削除する回数については1ページ最大20件なのでfor文で20回まわす事にした。この処理のために妙なコードになってしまったのだが、下記のような感じ。
<?php
function getdata($url){
header("Content-Type: text/html; charset=UTF-8");
mb_language("Japanese");
include_once('simplehtmldom_1_5/simple_html_dom.php');
$contents = file_get_contents($url);
$content = mb_convert_encoding($contents, 'UTF-8', 'auto');
$html = str_get_html($content);
$result = $html->find( 'div[class=datavalue],div[class=datavalue2]' );
$newArray = array();
foreach($result as $element){
array_push($newArray,$element->plaintext);
}
for($i = 0;$i < 20;$i++){
if(($key = array_search("詳細表示", $newArray)) !== false){
unset($newArray[$key]);
}
}
$arr = array_values($newArray);
$i = 0;
foreach($arr as $element){
if( ($i % 18) == 17 ){
$fp = fopen("test.csv", "a");
fwrite($fp, '"' . $element . '"' . PHP_EOL);
fclose($fp);
}else{
$fp = fopen("test.csv", "a");
fwrite($fp, '"' . $element . '",');
fclose($fp);
}
$i++;
}
}
for($i = 1; $i <=49; $i++){
$url = 'http://www.land.mlit.go.jp/landPrice/SearchServlet?MOD=2&TDK=&SKC=13109&CHI=&YFR=1970&YTO=2015&YOU=0&PFR=&PTO=&PG=' . $i . '&LATEST_YEAR=';
getdata($url);
}
?>
これで無事に動いて979件取得できた。このコードにより生成されたcsvファイルをサンプルとして下にリンクを置いておく。
なお、取得する件数が多いとタイムアウトすると思うのでその場合は下記のコードを加えれば大丈夫だと思う。値は秒数で指定をする。
set_time_limit(600);
当初の目的だった地価の分析を行いたかったのだが、かなり長くなってしまったのでまた次回改めて投稿をしたいと思う。